Louis-David Benyayer et Simon Chignard ont entamé une exploration de la valeur et de l’économie des données. Après un premier billet de présentation de Datanomics, ils proposent un éclairage sur le phénomène des proxies et son impact pour les entreprises et les individus. Ce texte est publié simultanément sur donnéesouvertes.info.
La question de la valeur des données est abordée plus largement dans Datanomics, les nouveaux business models des données (Fyp Editions, 2015).
Derrière la masse de données, les proxies
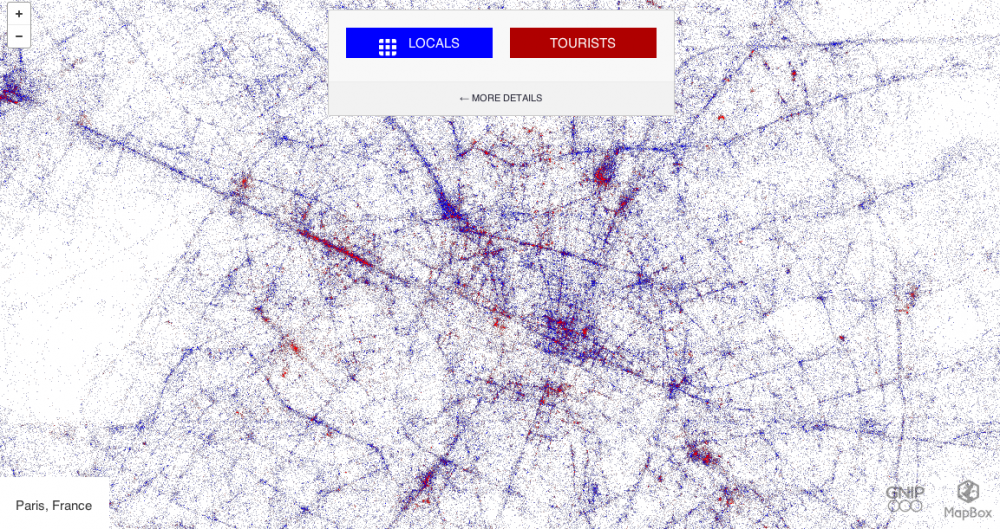
Le paysage actuel des données est le plus souvent abordé sous l’angle de la volumétrie. Il est vrai que l’accroissement spectaculaire des volumes de données collectées et stockées est la caractéristique première du Big Data. Cet effet de massification des données nous semble pourtant en cacher un autre: l’apparition des proxies, c’est à dire le fait que plusieurs sources très différentes puissent permettre de mesurer le même phénomène.
Prenons un exemple, sous la forme d’une interrogation: combien de personnes fréquentent chaque jour l’avenue des Champs Elysées ? Parmi elles, combien de touristes étrangers ? Plusieurs proxies sont disponibles: on peut utiliser les données de l’API de twitter et isoler la localisation parmi les métadonnées des tweets, consulter les données de localisation des téléphones portables, scruter les requêtes formulées sur le moteur de recherche Google, analyser les données du pass Navigo, celles des cartes bancaires utilisées dans les commerces de la plus belle avenue du monde, celles de Foursquare, … Sans même évoquer les procédés plus classiques, tels que les enquêtes réalisées auprès de la clientèle touristique ou le comptage manuel à quelques points de passage.
La généralisation des proxies nous semble constituer un fait nouveau: en raison de la mise en données du monde, de la multiplication des traces numériques et des dispositifs de captation, il y bien souvent aujourd’hui plusieurs manières de mesurer le même phénomène.
Dit autrement: la rareté laisse peu à peu la place à l’abondance – et surtout à la fin de l’exclusivité de la mesure. Plus personne ne semble à l’abri: même la mesure de l’inflation, a priori une fonction régalienne, se voit concurrencée par une mesure réalisée par Premise Data, une start-up co-financée par Google et Marc Andreessen. On a donc une compétition entre proxies, et bien sûr entre acteurs qui les portent !
L’erreur était juste
L’émergence des proxies ne va pas sans heurts. Avec la profusion vient aussi la confusion: Quelle est la meilleure méthode pour mesurer le phénomène ? Qui a “raison”, qui a “tort” ?
On comprend assez rapidement que chaque source de données comporte ses propres limites. Il est probable que les touristes étrangers aient désactivé le transfert de données (fort coûteux en roaming), réduisant d’autant la capacité à tweeter en tous temps et en tous lieux. De la même façon, les données du pass Navigo permettront de disposer d’une bonne visibilité sur les Parisiens ou Franciliens disposant d’un abonnement et moins sur les touristes de passage. Les données issues des cartes bancaires en revanche permettront de disposer d’une vision relativement complète sur les dépenses (mais moins sur les circulations !). Autant de biais dans les méthodes de mesure.
Chaque donnée nous informe sur une partie de la réalité et afin de pouvoir les analyser, il est indispensable d’en comprendre les mécanismes de production.
Ce que la science peut nous apprendre des données
Dans les discours et les pratiques, la donnée est toujours investie d’une objectivité toute naturelle : les données ne mentent pas ! Toutefois, dans certains cas, la donnée, à défaut de mentir, s’est magistralement trompée.
Ce fut le cas quand Google Flu trends a largement surestimé les prévisions de propagation de la grippe pendant l’hiver 2012-2013. Pendant de nombreuses années Google Flu trends – l’un des mythes fondateurs du Big Data – a été un très bon prédictif de la propagation du virus grippal aux Etats-Unis, bien plus réactif que la mesure officielle réalisée par les services sanitaires.
En décembre 2012, il a pourtant réalisé une estimation trois fois supérieure aux autres indicateurs et à la réalité de la propagation de la grippe. Pourquoi cet écart ? La raison est à chercher dans la source des données utilisées pour établir la prévision de propagation : les requêtes saisies dans le moteur de recherche. Or, à l’hiver 2012, le nombre de requêtes a fortement évolué en raison d’évènements extérieurs, rendant d’un coup beaucoup moins fiable l’indicateur produit par Google:
“‘(…) Several researchers suggest that the problems may be due to widespread media coverage of this year’s severe US flu season, including the declaration of a public-health emergency by New York state last month. The press reports may have triggered many flu-related searches by people who were not ill.” (Declan Butler dansNature, février 2013)
Dans un monde de données nous avons tous à nous préoccuper des conditions de production de la donnée, débattre et argumenter sur les sources et les méthodes. Nous avons besoin de développer ces capacités d’appréciation de la validité et de la fiabilité des instruments de mesure qu’on nous propose. Or le monde des proxies n’est pas celui de la recherche scientifique: jusqu’à preuve du contraire, l’algorithme de classement des pages web reste l’un des secrets les mieux gardés de Google !
Assez curieusement, la donnée brute reste un mythe vivace. On entend plus souvent l’injonction “show me the data” plutôt que la question: “explique moi comment ces données ont été produites”. On retrouve ici une tension entre le besoin de brutification et celui de contextualisation. Brutifier la donnée pour la rendre plus facilement réutilisable c’est une exigence. Mais pour autant c’est bien la compréhension du contexte de cette donnée – qui l’a produit ? pourquoi ? comment ? pour qui ? – qui fiabilise les traitements issus de sa réutilisation !


