
Cette année, la Fing et Without Model travaillent sur les défis économiques du Self Data et se concentrent sur l’incitation des organisations à restituer les données de leurs clients à leurs clients. Deux questions principales :
Quelle valeur peut créer la restitution des données personnelles pour les détenteurs de données ? Comment cette restitution nourrit-elle les business models actuels ou à venir des détenteurs de données ?
Pour élaborer des pistes de réponses, l’atelier du 30 septembre, réunissant différents participants – organisations, entrepreneurs, institutions, chercheurs etc – chez Cap Digital a permis de présenter une première cartographie des business models du Self Data et de travailler trois scénarios pour explorer les promesses de création de valeur pour les détenteurs de données.
L’atelier est articulé autour d’une hypothèse : la valeur d’usage des données personnelles pour les individu peut être considérable, mais la restitution des données personnelles aux utilisateurs sera surtout possible si les acteurs économiques y voient un intérêt :
- si les détenteurs de données constatent un impact positif sur leur BM ou construisent de nouveaux BM autour de la restitution
- si un écosystème de services et de solution rend possible la restitution
I – LA CARTOGRAPHIE DES BM DE L’ÉCOSYSTÈME DU SELF DATA
Afin de mieux comprendre l’écosystème actuel des services qui mobilisent aujourd’hui les données personnelles des individus, une première cartographie des BM de ces services a été préparée.
Elle a pour but d’imaginer des pistes de réponses à deux grandes questions : dans quelle mesure les business models des fournisseurs de service sont compatibles avec ceux des détenteurs de données ? Quelles alliances peuvent être réalisées ?
Une quarantaine de services font l’objet de notre étude pour déterminer leurs propositions de valeur (pour leurs utilisateurs), leurs modèles de revenus et leurs positions sur la chaîne de valeur.
Ces quarante exemples ne prétendent pas représenter de manière exhaustive l’écosystème des services, en effet, ce dernier est encore jeune et certains services repérés n’ont pas pu être inclus dans la cartographie car ils n’ont pas nécessairement de modèle économique stabilisé. Ce travail est donc amené à être mis à jour et enrichi régulièrement.
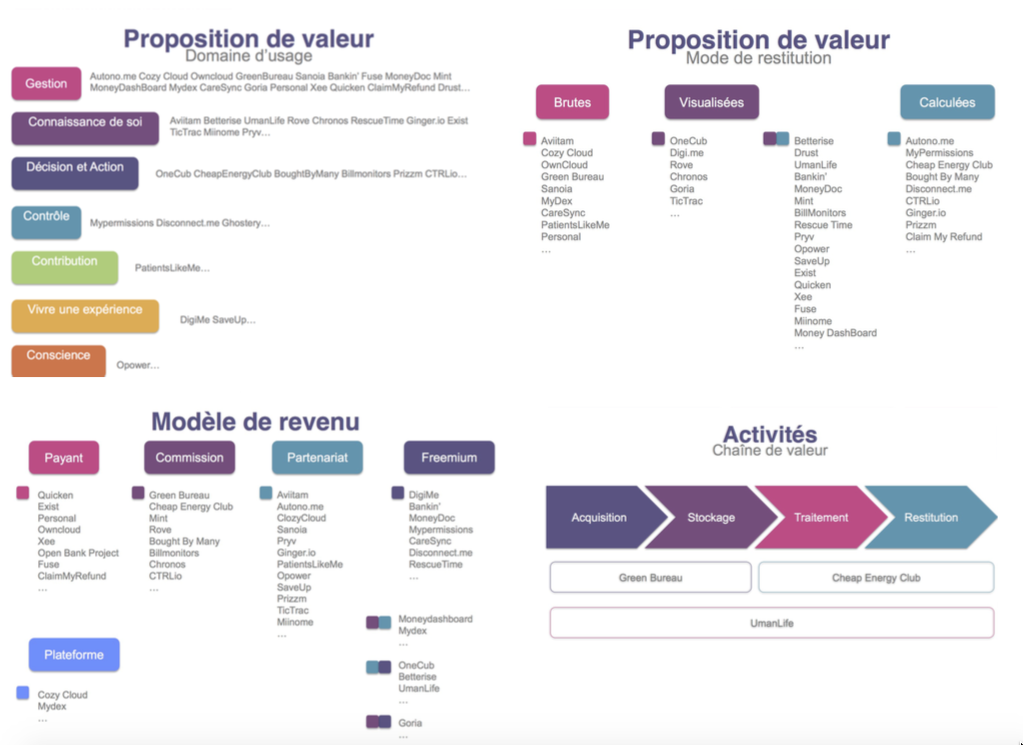
Vous pouvez accéder à la synthèse de la cartographie ici.
II – LES IMPACTS SUR LES BUSINESS MODELS DES DÉTENTEURS DE DONNÉES
Le Self Data peut avoir 3 impacts théoriques sur les business models des détenteurs : sur les revenus, les coûts et en matière de position stratégique.
Développer les revenus
Restituer les données aux utilisateurs va leur permettre d’indiquer plus facilement les produits ou services qu’ils souhaitent, ce qui est une piste pour vendre plus efficacement, synchroniser l’offre et la demande (“intentcasting”) mais aussi pour améliorer le bilan coût/bénéfices marketing en obtenant plus d’informations, plus facilement. Cela peut être une opportunité pour vendre plus cher, si le service ou le bien proposé répond particulièrement aux attentes de l’individu, s’il se voit proposer des recommandations particulièrement personnalisées. (“Hyperpersonnalisation”)
Réduire les coûts
Les données marketing se dégradent très vite en particulier parce que l’individu n’a pas intérêt à mettre à jour ses données. Dès lors qu’il y verrait un intérêt, il pourrait autoriser ses fournisseurs à s’abonner à ses mises à jour régulières, ce qui se traduira par une réduction des coûts de production, de mise à jour et d’utilisation des données.
Obtenir une position stratégique
En restituant leurs données aux utilisateurs, un détenteur peut s’arroger une position centrale dans un écosystème concurrentiel. Soit parce qu’il apporte une valeur supplémentaire à celle de ses concurrents directs soit parce qu’il se place ainsi dans un noeud de transactions entre les utilisateurs et l’écosystème de fournisseurs de services et solutions.
Retrouvez les slides de l’atelier qui reprennent ces 3 impacts
III – 3 SCÉNARIOS POUR EXPLORER LA VALEUR DU SELF DATA
Après cette présentation de la cartographie et des impacts, nous avons travaillé sur les ressources, compétences et partenariats requis pour réaliser cette valeur pour les détenteurs de données.
Pour y travailler, nous avons exploré trois scénarios complémentaires de stratégie de restitution de données personnelles aux utilisateurs.
Un acteur proactif qui favorise la restitution
Ce cas s’est appuyé sur l’exemple du CA Store, mis en place par le Crédit Agricole qui a créé une API sécurisée et ouverte (autour des données de compte et de virements) et a invité des développeurs à créer des applications à destination de leurs clients : quelles ressources et compétences sont nécessaires pour réaliser cette stratégie de restitution et explorer pleinement la valeur du Self data ?
Un détenteur bousculé par un nouvel intermédiaire
Nous avons été inspirés par Bankin’ qui fournit un service d’analyse des relevés bancaires en contournant les freins mis par les banques à l’établissement de ces services : comment réagir à ce nouvel acteur disrupteur ? Comment reprendre la relation avec l’utilisateur final ?
Le cas d’un détenteur de données qui collabore avec un acteur tiers (plateforme ou service)
Un détenteur de données (ex : EDF) fait un partenariat avec une plateforme de stockage de données personnelles (Cozy Cloud) et met à disposition de ses utilisateurs les données (ex : les données de consommation issues de Linky). L’utilisateur a un compte Cozy Cloud et une application, réalisée par le détenteur, tourne sur son ordinateur pour produire des analyses,. Cette application peut aussi utiliser des données qui proviennent d’autres devices que celui du détenteur (ex : Nest) ou encore d’autres détenteurs de données (ex : comptes bancaires). Comment établir le partenariat ? Quelles règles de partage de la valeur entre l’utilisateur, la plateforme et le détenteur de données ?
Vous pouvez retrouver la synthèse des scénarios ici.



